Approaches
Data structures determine what almost all computer programs can do. General purpose computing, called Artificial Intelligence as it approaches human capabilities, relies on Knowledge Representation data structures. This essay proposes what Knowledge Representation should provide, proposes structures, compares their capabilities with what is currently available, and describes a feasible path toward implementing the proposed structures. With the proposed structures, machines represent knowledge with conditional probabilities with closure logic statements using a limited set of predicates.
There are several appropriate general goals for Knowledge Representation development. What is not in those goals is part of their description. Furthermore, goals-driven and autonomous are not specifically called out even though some authors list them as goals. Almost all software is goal-drive, potentially adjusting goals according to a situation. Unless software is designed to be interactive, most software is also autonomous.
Machines should help people deal with everyday problems from making decisions to playing games. Helpful, apparently thinking machines, should deal with the unbounded nature of ideas, the complexity of ideas, and the uncertainty of the ideas communicated with natural language. Such machines would help people make rational decisions, communicating as needed to understand and be understood. A representation is part of that help.
Although a representation may enlighten us about human intelligence, such enlightenment is not required to be helpful. A representation can normatively describe what is required for human-like machine capabilities without describing or emulating humans. For instance, a useful machine does not need its own consciousness or to be embodied but may need only to model such concepts for dialogs. A machine need not make emulate human errors except perhaps as a decision to show appropriate emotional compatibility.
Normative goals for Knowledge Representation may not initially include some of the expectations of Artificial Intelligence. Normative goals might not initially include puzzle solving, game playing, or other specialized behaviors that seeming proved smartness but might be more representative of an idiot savant. Many of the publicized, but perhaps not especially helpful, Artificial Intelligence successes do not use techniques that a human would use but instead rely on specialized searches. Those successes may represent more of the being smart aspect of intelligence than the common sense of intelligent humans.
In order to be trusted, a representation should be open to inspection
using mechanisms that are transparent.
With dialogs or debugging, an answer to why
should typically be available as to the sources of a response,
their provenance.
This includes not only facts in a context but also any implications.
In order to be sound, a representation and the systems that use it should rely on well-understood, robust disciplines, such as Symbolic Logic, Probability Theory, and Decision Analysis. Using heuristics without a principled reason, such as providing an efficient search, should be avoided.
In order to demonstrate soundness, tests like the Winograd Challenge seem appropriate. Satisfying the Turing Test, which may involve producing errors to simulate human behavior, might not be appropriate for many applications.
Keep it simple, stupid
, Occam's razor,
Make everything as simple as possible, but not simpler
,
which is attributed to Albert Einstein,
should be appropriate development criteria.
A representation may not need to implement
the capabilities of an application that relies on it.
As needed for applications,
a representation might only store data and respond to queries
as a specialized database holding very general information.
The environment of a representation may handle many capabilities rather than the representation itself. For instance, a theorem prover might provide general inferences. The environment might calculate built-in operations, such as arithmetic. The representation itself might not supply a user-friendly interface but instead give an efficient application programmer interface (API).
Robotics is a different but overlapping technology that a representation might support but perhaps is outside of the core. Although algorithms for digestion, balance, or moving a limb are coordinated through the human nervous system, their details may be separate from the core of particularly human intelligence.
A system and its Knowledge Representation data structures should use as few resources, such as storage space, computing cycles, and communication bandwidth as possible. Using fewer resources potentially lowers cost and increases applicability but, more importantly, can give better security, including privacy, to its users. Applications using few resources may be more affordable and thus have wider applicability and be under the complete control of its user without having to rely on centralized servers, which have many security risks. If an application can limit its communications, it may continue to operate when communications are unavailable and avoid tracking when appropriate, such as in hostile environments including being stalked or otherwise threatened as sometimes happens with keepers of the peace.
In an environment where systems may serve multiple entities, those entities should expect that some information or controls would be provably secured from access to all but explicitly permitted entities. Entities should also be able to allow other explicitly permitted entities only access to aggregates of information.
Completely general purpose computing should deal with anything. Many use-cases examples have already been considered with varying degrees of success. This section categorizes general issues arising from these use cases and the larger problem space. These issues can then be sorted by importance into development goals. Developing any of these use cases would satisfy the helpful goal.
Software development examines use cases in order to drive requirements. Each abstract use case below may not stand alone but instead have overlap with other use cases. The use cases are all helpful to various communities. Because the requirements are so broad, broad categories can only touch on part of the scope. Basic natural language understanding is at least part of most of these use cases.
Assessment typically is an initial phase of working with data that may support subsequent decisions.
Personal information management — Storing and retrieving data for individuals such as names, roles, locations, calendars, relationships, resources such as money or inventory, and unusual information that is often opaque or just treated as a searchable string. Actions based on importance, particularly for a current situation, could assist individuals, for example, those with diminished mental capabilities from age.
Inference — Performing straightforward inference with propositions that may be combined without relying on additional propositions that were not already being attended to.
Diagnosis — Matching information for a situation to similar situations or to more abstract patterns, selecting the most relevant matches about issues, such as symptoms or hypotheses, and evaluating matches. Domains include medical diagnosis, forensic detection, net reconstruction, geological analysis, accounting, and market forecasting.
Situation assessment — Gathering potentially diverse data in order to identify patterns and abstract an overview, which may be acted upon. Assessment may involve accessing additional data that was not presented with the situation initially. For science, marketing, or production, statistics could be collected or analyzed, perhaps with external algorithms, to summarize by finding clusters, parameters, or other relationships, to categorize data, or to classify data.
Monitoring — Watching changes in the environment to discover if they are expected or coordinated with other actors, for example, to provide security or identify an opportunity.
Traditional learning — Analyzing information, primarily arriving as words, perhaps supplemented with diagrams, images, or data in other formats, in order to gather new knowledge, perhaps as a collection of statements, especially for longer-term storage and later retrieval that may guide future actions. Decisions about what to keep and later consider may be based on goals internal to the system.
Decisions are made after analyzing data.
Decision support — Machines can assist humans by suggesting alternatives along with the benefits and costs of each. Each alternative may predict many scenarios with varying probability that could result from decisions. An interlocutor may ask for additional information, such as new information or the details being used to evaluate the alternatives. The decisions may come from objective evaluations or from subjective ones as for recommendations. Group decision support could include:
Automated decision-making — When the values of an interlocutor are understood, a machine may execute parts of larger plans without further intervention. Business logic could be elicited interactively. A machine may also decide details as needed or actions for unusual situations, such as giving an alarm. Honoring appropriate constraints, machines could handle electronic commerce and auctions, even for financial instruments like equities.
Planning — Machines can order events in time or objects in space according to dependencies between the events or objects and resource usage. In some situations, a few orderings will dominate with a straightforward evaluation but in others a machine could evoke specialized algorithms, after appropriately structuring inputs, and interpret any outputs. Afterward, plans may need adjustment, elaboration of details, or complete rework during execution. Plans may include slack or have alternatives to allow for uncertainty, particularly for multiple actors. Motion plans along with course corrections may have multiple spatial and temporal resolutions.
Integrated applications — Machines can combine sensor or communication inputs to make on-going decisions for applications such as robotics, objects in the Internet of things, manufacturing, security monitoring, and many others in a changing environment with shifting needs. Machines could participate in a transition from manual processes to more automation of existing environments.
Natural language is often desirable for human interaction with machines. It is a gateway to ideas. Beyond current dialogs, which are often limited to two steps, query and answer, and many not involving syntax, natural language presents some specialized issues.
Information retrieval — A dialog returns results from a query to unstructured, structured, or semi-structured hybrid information. A query on unstructured information may initially suggest many meanings, which can be focused, perhaps through negations, to documents, parts of documents, or specific answers. A query on structured information may consider metadata, such as database column identifiers, to be narrowed to a desired collection of answers, perhaps a singleton.
Summarization — A collection of documents, possibly a singleton, may need a presentation of just the most relevant information according to a particular situation.
Web understanding — Non-specific searches are needed to prepare to answer queries, to identify unexpected information, or to establish norms for good and bad behavior, such as excessive advertising (spam) and malware. For the worldwide web vastness, such searches would be automated with extremely little intervention. Collected information could be kept in a longer-term intermediate form for later querying and scanning as in collecting statistics. Retrieval could display the collected information without off-topic information such as advertisements.
Document editing — Humans could be assisted with the communication of their ideas to others. Beyond the denotation and connotation of words, the representation of documents can include aspects such as themes, organization, style, grammar, and word choice. Through dialogs, those aspects; conventions like punctuation, capitalization, and spelling; and even poetic choices such as meter or rhyme could be guided according to differing situations, such goals or audience. A model of the author’s intent and audience expectations could inform changes. Domains could include forms, fiction, reporting, persuasion, or proposals.
Translation — Machines considering the generation context of natural language expressions can produce syntactically appropriate communications that not only has appropriate surface-level denoted meaning, idiom, and metaphor but connotation, tone, dialect, jargon, and other elements of style. A good translation may have significant changes from the original beyond syntax manipulation and word substitution. However, the impact on the audience, who would be modeled for both the original and translation, should remain nearly the same. Translation alternatives should be weighed with many criteria.
Machines can direct other entities for more efficient overall creative processes. In particular, improved software development can radically improve capabilities.
Development management — Machines can do more to assist project managers and developers communicating with each other and other actors. Requirements can be expanded, tracked, and changed according to the situation. Implementation strategies including tasks and milestones can be suggested, evaluated, and sequenced. Resources can be allocated. Tasks, resources, and issues can be tracked. Resolutions can be suggested for issues. Quality can be improved by collecting metrics and by generating more thorough tests that cover the requirements. Throughout, development and management may be integrated with any existing tools.
Automated development — Machines may perform many routine parts of a process but still allow monitoring and changes as requirements change. Initial elicited requirements, which can be subdivided and elaborated into tasks, could be adjusted as the situation changes. Any existing software or other instructions could be parsed to determine intent. Appropriate choices could be made where requirements are silent, contradictory, or misleading. Machines can evoke and interpret more specialized algorithms when appropriate. Humans and machines would interact wherever machines were not capable. A more efficient dialog interface can be understood more easily, allowing human access to implementation decisions.
Program synthesis — Machines can create instructions for themselves from supplied or internally generated requirements. After creation, machines might execute such instructions without requiring intervention. Requirements could go beyond a primary function to other considerations such as exception handling or time to completion for one-time versus repeated use. The requirements can be converted into modules that may be subdivided into code fragments. The resulting code may be verified and reorganized for efficiency, human understanding, and best practices. Code metrics could be considered such as complexity and requirement coverage. Modules could be tested in constrained environments. The development process itself could be modified to meet overall tradeoffs such as between creation speed and reliability.
Machines can sense environments and interpret any measurements. Sensing can include sound, images, including video, positions and their orientations including part positions and motions, and chemicals for analysis akin to smell and tasting.
Some senses provide a huge amount of analog data to be sampled. For efficiency, such samples may need significant preprocessing before suggesting models that may abstract even tiny parts of the overall input. Matching data with patterns can produce abstractions and certainty evaluations. Once abstracted, the partial models may be combined recursively into the most likely interpretations of the environment. Partial interpretations could also be compared with the sensed data, perhaps adjusting sensing parameters, like gain or lens focus and aperture. Such interpretations may be assessed and appropriate decisions made.
Machines can discover or produce new information beyond what is found by examining large amounts of data and then determine actions. Abductive reasoning can extrapolating what is represented, perhaps ignoring some constraints or combining disparate information, into new possibilities.
Analogy — Humans use many analogies to describe situations where direct meanings or connotations are insufficient. One common analogy is metaphor, which uses descriptions that only partially match situations. Many dead metaphors are used so frequently that their meaning becomes nearly fixed. But other live metaphors require interpretation between a typical meaning and the likely possibilities of a situation. Machines may generate analogies through abductive reasoning. Machines with a model of expected interpretation could generate metaphors and other analogies in dialogs, summaries, and other natural language output. Sarcasm and some other rhetorical expressions may rely on similar mechanisms.
Creativity — Imagination and creativity may come from a combination of contexts. Some theme may be expressed with patterns that have not been applied before. Even though the theme and patterns already exist, the combination is new. Such combinations could include products, stories, images, or nearly anything else. The guidelines that the patterns present would shape the expression and elaboration of the theme.
Problem solving — Many problems come without significant prior constraints. Problems often must be refined from something vague to a more actionable issue, perhaps by narrowing scope or by elaborating details. Resources may be identified that go well beyond their intended use by selecting only resource properties and other relationships that are relevant to the problem. Creating a plan to apply resources may also need similar refinements.
Use cases specify requirements for Knowledge Representation. The following presents those requirements in a potential order of importance. What comes first may be addressed first during initial development. Throughout the uses cases is a need to process natural language, both its semantics and syntax.
Assessment and language use cases especially show the need for an unlimited capability to represent nearly anything, particularly what comes from natural language. Anything may range from the usual or simple to the rare or complex. It’s not enough to just index statements. Anything that is represented may have properties or relationships to an unbounded model. Use cases like diagnosis, summarization, or web understanding need to identify details and commonalities, going beyond denotations. Although knowledge might be limited to useful information interpreted from data, Knowledge Representation covers anything needed to arrive at useful information. The approach to providing basic capabilities comes first because it directs the entire implementation.
Almost all of the use cases need access to install new statements and retrieve what is already represented. The accuracy of queries may range from finding exact matches that fill blanks, to finding similarities, to collecting statistics, such as a count. Similarities could include statements that are more generic than the details of a query. Just beyond being able to represent information is an immediate need to retrieve what is represented.
Context, the situation where some part of a representation applies, needs an appropriate representation within the overall organization. Use cases have many different contexts.
Because handling context fills out the basics of the organization of representation, it comes early in implementation.
Perception, assessment, decisions, and language often involve uncertainty. Uncertainty involves what is not known. Uncertainty arises in many ways. A situation may not have been measured, typically because it hasn’t yet happened or is yet to be perceived. With language and assessment, the data may be ambiguous with more than one interpretation.
Measurements may be unreliable or not precise enough. Uncertainty has several aspects to be represented. Using the capabilities of the representation and its ability to describe situations, the available alternatives should be represented. Among those alternatives, any likelihood ordering that they have should be represented. Beyond that, the likelihood of the alternatives should be quantifiable with a strength and information about how strongly the strength of alternatives is held. Typical statistical measures are mean and variance or standard deviation.
Because handling uncertainty depends on basic capabilities and context, its implementation may be delayed until after them.
Decisions and development depend directly on judgment. Those use cases weigh the expected importance of alternatives with potentially uncertainty outcomes. Money or other resources such as computation time may measure importance. For some use cases, the computation time or other resources such as storage or user attention may be significant. Those use cases may make meta decisions about the process of making decisions. The cost of gathering information may be weighed in judgments. For the monitoring, automated decision-making, and automated development use cases, importance may significantly vary with time, such as when exploring alternatives. One reasonably good judgment about an alternative could obviate the need to explore others. Since some alternatives may dominate others or have a good-enough importance estimate and judgment may depend on uncertainty, for initial development more specialized judgment making may come after handling uncertainty. Any ethics that judgments consider may come from the information provided to make judgments rather than system development.
Traditional learning, web understanding, program synthesis, and novelty uses cases require permanently adapting to situations with new information including changing needs. Again, the representation may need to represent anything! Once implemented with an appropriate interface, adaptable systems should not require significant outside intervention to make changes. Since these use cases involve judgment but may not need to operate at scale or with great efficiency, they may be fully addressed later but not at the end of development.
Information retrieval, web understanding, and situation assessment may require more computational resources than are available on a single machine. These use cases with their practically unbounded domains may operate at a larger scale. Even the resource demands of personal information management could be quite large if data formats such as video are considered. However, delaying development of such use cases may be appropriate until other infrastructure exists. Only the requirements of persistent storage, which should be needed eventually for scaling, should justify earlier development to facilitate testing.
Any processing can benefit from efficiency. Some efficiency considerations, such as supporting algorithms that could allow parallel processing, may be important from the beginning of development. However, optimizing for efficiency probably should be delayed as long as practical. If algorithms can return answers within a tolerable amount of time, then they are fast enough to support most research. Otherwise, optimization could drive decisions too early in the development process. Even potentially time-sensitive use cases like personal information management, monitoring, automated decision-making, automated development, or integrated applications including robotics may be performed fast enough to be minimally useful, tolerated, or even embraced. Faster or more hardware often ameliorates efficiency concerns. Thus efficiency may be addressed last.
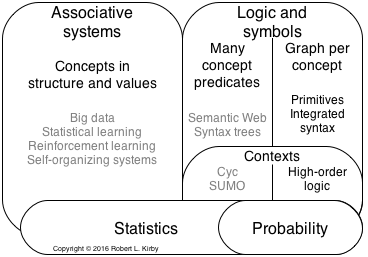
Knowledge Representation data structures with a limited set of Curried predicates, called primitives, in closure logic expressions within conditional probabilities may satisfy the general goals for Knowledge Representation and the specify requirements of the use cases, which involve natural language. Each aspect of the structures has advantages. Furthermore, this combination does not individually or pairwise satisfy the goals and requirements. After showing how each aspect contributes to the basic capabilities, other Knowledge Representation requirements and goals will be addressed.
Relying on a quite limited set of Curried predicates, here called primitives, is new, even though similar approaches were already suggested. A predicate is a function from a parameter list that models a universe of discourse, its domain, to the Boolean values, true or false, its range.
The first argument of each primitive is Curried into an unlimited collection of fixed predicates, which form the ground of logic expressions. The currently envisioned Curried argument types may be nil, strings, internal identifiers, real numbers, or vectors of real numbers. Strings and numbers, which both are theoretically unbounded, should be enough of a base to form expressions for any concept to be discussed, even other concepts that are unbounded.
The definition of each primitive will unambiguous as far as possible. The definitions restrict meaning far more than a primitive name as used in natural language may suggest. By convention, each primitive only supports a single type of Curried argument and a specified type of parameter list. Parameter zero of a predicate is always the containing closure as discussed below. The other parameters may model any entity both physical, which includes processes and other physical situations, and abstract, which includes non-existent or paradoxical concepts. The extremely limited set of primitives with their restricted definitions helps achieve parsimony.
Having completely non-overlapping representations through primitives seems impractical. For instance, natural numbers can be constructed from sets. However, the applications that use the representation can maintain mostly preferred usages, such as using natural numbers for counting. Preferring usages rather than requiring an orthogonal set of primitives, the coverage of primitives for logic expressions may be explored more easily to include modeling anything from any differentiation, from abstract to physical, from physics to emotions, from details to the holistic, from syntax to denotation and connotation, from immediate to meta. With all possible differentiations covered, applications can adapt to anything, a Knowledge Representation requirement.
By convention, beyond parameter zero, up to three (3) parameters may have different but fixed meanings. As a modeling and computational convenience, variable length parameter lists may have up to two (2) initial parameters with different but fixed meaning beyond parameter zero followed by a non-empty list of parameters with more uniform roles. By convention, parameter one is typically given a role that would be said first. A parameter that represents an aggregate should immediate precede other parameters that form the aggregate, possibly a variable-length list. For example, parameter one of a sum would total all following parameters. More generally, instead of having functions, predicates with the first argument as the would-be function range serve as functions. Such conventions improve understanding, a Knowledge Representation goal.
Matching entities is one of the most significant operations that a representation can support. When parsing natural language, entities have syntactic and semantic roles that all should be aligned. Each entity may have several, possibly quite different presentations. Moreover, entities that are not explicitly mentioned in one phrase may nonetheless need to be identified in another phrase or in the surrounding context. Automated theorem proving needs to perform similar matching between formal logic expressions. Naming entities, which be done somewhat arbitrarily in rule-based systems, may not scale. Usually such matching needs heuristics to guide the search for matches. Each distinction associated with primitives can provide a different heuristic, which is linearly combined with others. More substantial differences, such as between physical and abstract, can be treated more strongly than lesser ones such as a minor difference in measurement, dark pink versus light red. Better heuristics may so substantially improve search that efficiency, an ordinarily longer-term requirement, goes from unacceptable to acceptable.
With fine distinctions, the conditions of statements can use the most general applicable description. If statement conditions have more specific descriptions than are needed, then a representation might store redundant statements, working against being small, a Knowledge Representation goal. If both generic and specific condition descriptions are needed, then the generic can apply as a default.
Logic, an ancient discipline, as a set of rules, forms the definition of principled. Logic statements, which say the least possible, are parsimonious and can lead to a very small system but that still may be understood. This approach is designed to support parsing natural language including its syntax.
In order to improve understanding, particularly for expressions where first-order logic (FOL) is insufficiently expressive, the base representation has similarities with the Conceptual Graphs of John Sowa, which followed the Existential Graphs of Charles Sanders Peirce. Rather than rely on the quantification over predicates that closure logic uses for arguments of predicates, the base representation has situations as arguments of predicates. Those situations contain predicates that only need be satisfied when the situation is satisfied. This base representation is called closure logic here.
Having predicates as arguments of predicates is a defining feature of higher-order logic. It removes the restriction on argument types of FOL. But predicates are relations, which are a subset of a cross product of arguments of each type and the Boolean range, true or false. Cross products seem like a more complex notion than a situation, context, or setting. Humans may find modeling easier using predicates only in a situation rather than more generally as any argument of another predicate.
The base representation uses very few connectives. Within any situation, which can be the top-level situation, is a conjunction (AND) of all predicate instances. Each predicate takes a non-empty list of entity variables as arguments. Each predicate instance has a zeroth argument that specifies its parent situation. Negation (NOT) appears as a predicate. Other logic operators such as disjunction (OR), material implication (->), and logical equivalence (<->) are constructed from extended De Morgan’s Laws using negation on situations. As mentioned earlier, predicates sometimes serve as functions. The preferred representation is like a conjunctive normal form, with redundancies, such as some double negations, removed.
The base representation has no default quantifications or types. Variables, which model entities, are all free. Predicates on an entity specify any types. Asserting a predicate like abstract or physical serves as existential quantification (∃) on an entity. A predicate for the size of a containing collection can specify uniqueness. Negations and their situation arguments may construct universal quantification (∀). No constants are declared. Instead, somewhat like skolemization, an entity may behave like a constant if predicates sufficiently constrain the entity. Paradoxes or other inconsistencies may be represented. Enclosing applications may interpret the base representation for any purpose such as automatic theorem proving. Tarski semantics may be appropriate rather than Herbrand.
A highly restricted subset of Knowledge Interchange Format (KIF) is available for the external text representation of expressions using variables, predicate instantiations, and quoted expressions for situations. The KIF external representation gives a clear, unambiguous presentation. A graphical format is available manually.
Situations directly satisfy the requirement of use cases
to represent contexts.
Situations expand the expressiveness of the representation beyond
that which is available with FOL.
Many words such as
can
, may
, want
, propose
, suspect
,
think
, believe
, imagine
, hypothesize
,
estimate
, and overstate
would otherwise be difficult to express.
For each such word, a predicate argument can be a situation.
A situation may also be called a
context, statement, setting, state, session, goal, plan, proposal,
suspicion, thought, belief, hypothesis, or other name depend on its use.
John Sowa originally named them descriptions.
A situation includes predicates that are only necessarily true
when the predicates that have the situation as an argument are true.
When shown diagrammatically as entity boxes containing predicates,
situations may appeal as a structural representation of some ideas,
leading to better understanding.
Modal logic, which in typical examples covers necessity and possibility, needs expression syntax beyond FOL. Instead in this base representation, using the situations of a few predicates subsumes modal logic. Plans and processes, which describe changes in state over time, have a straightforward representation without needing special considerations for time. Figures of speech such as metaphors may include a situation where only some aspects of a statement will be accepted.
Negations, which require special handling by applications of the representation, are nonetheless treated as situations in order to have a simpler, more uniform approach. The condition and conditionee of conditional probabilities are also situations but have a special status, which is discussed below, when used as outermost situations.
Frames, which gather the invariants of a collection of situations, sometimes may have an explicit context. However, the constraints of a frame may often become part of the condition of a conditional probability without an explicit context of its own.
The combination of primitives and HOL into an assembly language of ideas provides unrealized opportunities. When each idea that might appear in an ontology hierarchy is decomposed into a preferred representation, then the relationship between ontology items becomes apparent. When an item is more generic, it should have fewer constraints than more specific items. Thus a graph of the more generic item's representation should be a subgraph of the more specific. This could give a more principled approach to generating ontology relationships and a double check using existing ontologies of proposed representations.
Finding relationships between ideas should be more robust. Two ideas treated as graphs each have a common subgraph that should represent what the ideas have in common. Searches for similarities, such as between a query and document summaries, could identify the largest subgraphs in common while also accounting for conflicts. Search results could include more appropriate commonalities ordered by strength that relies far less on keywords, crowdsourcing such as link counts, and the effects of search engine optimization (SEO). Crowdsourcing could still help evaluate trustworthiness but content would be king!
New information for the representation can be added using the assembly language of ideas. New combined ideas or new refinements become either merged graphs or subgraphs of the graphs of existing representations. Such assembly satisfies the adaptability requirements of the use cases.
Anything that needs to be represented should be possible by extending to unlimited possible combinations of predicates and their variable entity arguments, which include situations. The base representation provides an ultimate reductionist model for general purpose computing, especially that called Artificial Intelligence.
The base representation was developed to support an initial application of parsing natural language. The detail of the representation allows precise matching of nearby words and phrases. In many cases, mismatches of details may discourage inappropriate matches of meanings. Not only should the denotations, which a primary entity variable of each expression represents, match but any secondary entities that are part of the description of the denotation might be matched too. Matching connotations, such as sentiments, could also contribute to appropriate matching.
The base representation could also include syntax statements in HOL rather than using an alternate external syntax such as TAG, CCG, or unification grammar syntax. Since the base representation can represent syntax rules, it should be at least as expressive as an alternative external representation. But by integrating syntax and semantics into combined matching approach, the best of each is available for making parsing decisions at each step. Separate representations of semantics and syntax encourage one to be more completely applied before the other, potentially making search less efficient. An integrated match can produce a better-informed conditional probability of a match.
Although uncertainty statements could be represented entirely within HOL, top-level estimates of conditional probabilities are represented separately to better satisfy the goals and use-cases requirements. Probability, which has principled foundations, is more expressive than other uncertainty measures and can support judgments through utility calculations. Conditional probability estimates can be readily understood as providing contexts. They can be organized to provide useful, secure, and efficient access to statements at scale. The following gives details how they can satisfy the understandable, principled, and secure goals and the capability, access, context, uncertainty, judgment, scale, and efficiency requirements of use cases.
Probabilities abstractly model many real world situations. Probabilities are real numbers between 0 and 1 inclusive assigned by a probability function (usually denoted P) from a domain of measureable sets called events that are subsets of a set called a universe (Ω) where P(Ω)=1, P(∅)=0, and if A∩B=∅, then P(A)+P(B)=P(A∪B). Outcomes are members of events. (In this essay, events are sometimes designated with the logic expressions that specify the outcomes of the event.) Probability theory is a principled discipline with an extensive elaboration including many distributions, joint and conditional probabilities, and strong connection to Statistics. That connection to statistics, particularly for describing frequencies of events, gives probabilities grounding not had by other uncertainty measures such as fuzzy measures and ad hoc approaches.
Statistics are collections of measurements that are compared to probability models. Statistics, which sometimes include Bayesian a priori estimates, are used to estimate parameters of probability models. Those estimates are sometimes the subject of other models called higher-order probabilities, which may also have estimates. Dempster-Shaffer theory is another approach that characterizes bounds on the estimates, which this approach does not specially support. Of particular usefulness are estimates that behave like probabilities such as the parameter of a binary set of events. This knowledge representation specially handles those estimates for conditional probability models as top-level statements. HOL represents any explicit probability models within statements.
The specially treated, top-level statement, conditional probability estimates handle many flavors of uncertainty: unknown information, ambiguity, vagueness, approximation, and oddities including production errors and black swans (highly unusual events). A single conditional probability statement may have more than one estimate based on different calculations, ease of use, underlying data set, precision, suspected instability, inconsistencies, or other criteria. The estimates exclude the zero (0) and one (1) endpoints of probability range intervals in order to avoid some computational issues. Instead, an epsilon-like marker may apply. A preferred conditional probability statement would exchange any outermost negation of a conditionee for an appropriate probability (1-p).
The representation provides partially sorted specific-to-generic access to all more generic conditions of a query condition. For any condition, the representation provides access to all of its conditionees, their conditional probability estimates, and meta data. Since any of this may be needed to determine estimates and install new conditions, possibly the most frequent uses, such retrieval should be available in near linear time. Some more specific conditions of a query condition may also be retrieved when appropriate indexes are installed. Even without such indexes, a query using a retrieved conditionee and a condition may be enough to get even more specific appropriate conditionees.
The relationships between directly more specific and generic conditions form a lattice that applications can navigate in either direction. Although it would not be practical at scale to index all more specific conditions from any more generic condition, applications may be able to navigate to more generic conditions to find appropriate indexes. Such navigation may implement some fill-in-the blank queries and adaptability requirements.
The representation itself would be the primary user of some meta data, such as indexes. Applications could use history and other provenance meta data to resolve inconsistencies and estimate conditional probabilities. Applications could store partial estimate calculations. Applications could install triggers to evoke processing after changes such as to estimates or additional conditionees.
The representation could limit installation of some kinds of propositions on conditions to privileged applications. Only privileged applications could later retrieve such information. Enforcement of such protocols could provide security.
In order to operate at scale and provide long-term storage of specified statements, some statements can be stored in less volatile storage. To promote easier understanding and development of the representation, both shorter and longer term storage should cooperate and could share mechanisms such as internal formats and indexing.
The conditions of the lattice also form a directed acyclic graph (DAG) with more generic conditions closer to any roots and more generic conditions closer to leaves. This structure may contribute to parallel processing efficiency, where applications would need transactions. Transactions on either volatile, like in-memory, or less-volatile storage, like database management systems, may be split between those on conditions and their indexes, which may be done first, and those on conditionees. Optimistic transaction management, such as software transactional memory (STM) for volatile storage and write-ahead logs (WAL) for less-volatile storage, is likely to avoid access rework. The conditions and their indexes, which are more likely to have conflicting changes near a root, generally should have fixed size, smaller transactions occurring one at a time, which typically complete more quickly and avoid access starvation. Conditionee changes, which application transactions may commit together, are more likely to be separated from other transactions and may be started only after any of their condition transactions are complete. Less-volatile storage maintenance, such as pruning a clustering, may occur mostly without conflicts when there is enough space available. These transaction characteristics should allow efficient approaches regardless of scale.
The condition and conditionee of conditional probability statements are similar to the premise and consequence of inferences, particularly like rules with declarative consequences of some expert systems. When considering uncertainty, many facts are easily understood with a pattern of if-something-then-something. Such statements may be easier to elicit and then encode. The condition and conditionee also represent situations of HOL, which support context requirements.
The detailed representation allows the most generic condition to be used for each statement, which improves the possibilities that each fact will have the widest applicability in this parsimonious representation. When a conditionee may have different uncertainty measurements in different situations, the detailed representation allows selecting the most specific representation. When no appropriately specific condition is available for a conditionee, the most specific condition, even if it is quite generic, can still serve as a default, which provides a principled approach to default handling. Providing defaults gives an approach to some of the issues of the frame problem, common-sense defeasible reasoning, and non-monotonic logic. Second order probabilities can quantifiably alert an application to the weakness of such a default statement.
For some conditionees, more than one condition may apply but without any condition being more specific than other conditions. An application can readily identify such an inconsistency from query results and combine probabilities in an appropriate way that could even use any further conditions that are more generic in the query results.
If a distance measure between conditional probability estimates for a single condition is too large, then an application could decide on alternative actions rather than trying to immediately calculate a combined estimate. For instance, the absolute value of a logarithmic difference of competing probabilities might be larger than a threshold (|log(P(B|A1)−log(P(B|A2))|>t). The capabilities provided by probabilities on more precise statements should improve the ability of an application to make appropriate decisions even when encountering inconsistency.
With appropriate instability checks, probability estimates can be calculated linearly without the exponential computation complexity of Bayes nets. When parsing natural language combines many different semantics and syntax alternatives, a quick calculation can have more value than a more precise calculation that takes more time. Moreover, maintaining conditional probabilities for negative conditions may not always be required unlike Bayes net calculations. However, if a more precise calculation is worth the cost, then a complete Bayes net calculation could still be available.
Conditional probabilities can contribute to calculations of utility, which is expected value. Some techniques can make different kinds of value commensurate. For judgment requirements, utilities can provide a principled approach for decision-making. Utility can also provide a well-motivated heuristic for search, which is part of processing for many use cases. Heuristics can have an overwhelming effect of search efficiency. When parsing natural language by combining representations for neighboring word or phrase meanings and their syntax, identifying entities that should and should not match may need a heuristic search, like that which the A-star algorithm provides. Overall processing decisions, such as which step to apply, may be more efficiently chosen with a well-motivated heuristic. If value changes quickly, such as when any sufficing solution is found so that others are less important, then applications might maintain value and utility separately.
Conditional probabilities with
whose predicates come from
a limited set of primitives
The semantic web OWL methodology and ontologies like SUMO assume the bulleted items.
Tractable means easily managed or controlled (probabilistic) rather than running in polynomial time (deterministic).
Associative approaches gather large quantities of groupings, often of numbers and attributes, from typically even larger amounts of data or with iterative computations to identify patterns of associations. Because they may not name entities, associative approaches are sometimes called sub-symbolic. The following first generally characterizes those groupings, identifying some common approaches, and gives examples of how they are used. Issues are discussed for the crowdsourcing techniques on which many of the approaches rely. Then the approaches are evaluated on meeting requirements for the uses cases and the goals suggested above.
With associative approaches, the representation is inseparable from the algorithms. The algorithms have similar characteristics using large amounts of initial calculations with many result values. The preprocessing of many iterative algorithms assigns initial numbers to small groupings of input data. The iterative algorithms repeatedly update these groupings. Other algorithms gather statistics for large quantities of variables from very large data sets.
With text, which typically either comes from crowdsourcing or scanning a large corpus such as the web, preprocessing may identify groups of nearby words, sometimes called N-grams, either with or without stop-words, which are the most frequent natural language words; possibly identify syntax, lemmas, and synonyms; and save context information.
With sensor data such as imagery and sound, some preprocessing may occur such as gather histograms, segmenting, Fourier analysis, or other feature extraction. However, sometimes just the raw data may be used.
Some algorithms considered here are iterative taking repeated passes over the data until the results become stable. Other non-repeating algorithms collect statistics over huge data sets. The algorithms are amenable to parallel processing, which breaks the representation into shards, which are eventually combined, or to pipelining the processing. Either technique or both together may greatly speed processing and allow processing of amounts of data that cannot be contained within current machine memories. Depending on the use case, after the results stabilize, either post processing uses the results directly or querying selects from the results.
The algorithms are designed to work without intervention. The quantities of updated groupings are typically so large that they cannot be usefully inspected. The groupings are not given meaningful names such as symbols. The numerical values of these groupings embed the structure of the results. The results come from association rather than inference.
Researchers in Artificial Intelligence primarily used some older iterative techniques such as relaxation and simulated annealing for perception tasks such as image segmentation and classification. Relaxation starts with a network of connected nodes, sets of possible labels for those nodes, and constraints between nodes. During iteration the constraints are relaxed as fewer labels can satisfy the constraints. Relaxation experiments included layered networks. Simulated annealing starts with a labeling, which is randomly perturbed during each iteration by lesser amounts.
Statistical methods continue to be used such as statistical testing, statistical relational learning, supervised learning, and Markov processes like Markov decision process (MDP). Such long-standing techniques with a well-studied heritage are now being applied to big data sets.
Natural processes inspire some techniques such as genetic algorithms and reinforcement learning. Genetic algorithms start with groupings that are randomly perturbed, like with simulated annealing, to try to find better fits to the data. Reinforcement learning rewards small changes to groupings that could better fit together.
Brain architecture inspired neural nets, originally named perceptrons, which have led to deep learning techniques. Deep learning starts with a layered network of nodes derived from data. During each iteration, numbers associated with interpretations of the nodes are adjusted based on neighboring node values both within and between layers. With sufficient training, the numbers stabilize and the values of some of the nodes can characterize the inputs.
While most details are proprietary, iterative approaches appear to process natural language for several applications:
These dominant, successful technologies appear to process natural language with iterative associative algorithms. Deep learning is being used with some success for perceptual tasks, particularly computer vision, with an emphasis on using parallel hardware such as GPUs to speed up processing.
Associative approaches for natural language handling need large amounts of training data. Crowdsourcing collects such data from available sources, much of it available to anyone but some from protected sources such as from mobile phone users. The use of such data compromises the security of supposedly protected users but is nonetheless commonplace.
Adversaries of system integrity can compromise the training data. SEO practitioners game search engines in an on-going battle. Public chat bots have been trained to make inappropriate statements (Microsoft Tay). Groups with an agenda can make something appear either more or less popular or trusted than the public at large would find it (on-line election polling).
Crowdsourcing votes on trust and popularity such as frequency. Collecting a network of trusted sources may weight the votes to improve such estimates but is far from infallible. Moreover, if the crowd is wrong, its judgment is apt not to be assessed with anything, such as logic, other than statistics. Biases can go unchecked. Groups with like opinions can reinforce themselves and will appear trusted, sometimes called a bubble filter. Biases may become even more severe if the group interested in an area is small since statistics may have high variance.
Crowdsourcing can have difficulties with many data groupings, such as documents, that are nearly the same. For instance, if a document has many revisions over time, then identifying the time of a change or the latest version of the document of a particular theme may be difficult for an associative approach. Associative approaches can have difficulty with data that varies logically but maintain a similar pattern.
Advocates of crowdsourcing dismiss issues with statements about how not enough data has been collected yet. But many collectors already have access to the entire public Internet, a vast collection. Moreover, some data, such as proprietary information, may never be openly available. Sometimes common sense statements may never be explicitly placed in the corpus and thus are not captured. A novel situation may have nothing appropriate in the training data either.
Other media may present similar issues with crowdsourcing. For instance, imagery used to train may come from only one point of view, such as eye level. When another point of view, such as mostly overhead, is queried, since there is no explicit model, training may be insufficient.
The use cases listed above suggest requirements for a knowledge representation. Associative approaches efficiently provide access to the representation while handling data of enormous scale.
Associative approaches partially meet the use-cases capabilities requirement. For example, the most effective general search engines return reasonable results within the first few tens of items for around 90% of the queries but fail for the remaining 10%. Summaries of each result document usually provide a usable impression of the contents by focusing on excerpts that contain the query keywords.
Users are habituated to the inadequacies. The queries mostly give users what they are after. Users are willing to sift through many irrelevant results to the actual intention of their queries. The positive feedback of getting answers obscures the inadequacies of the results.
Queries that might better be expressed with logic, such as logical negation rather than excluding a string in result documents, are not really available. Furthermore, more complicated concepts that cannot be described with a few keywords seem unavailable for search. Narrowing the results through interpretation of the actual requirements of a query is left to a human user.
Associative approaches probably meet the use-cases uncertainty requirement. These approaches identify alternatives to answer queries and rank-order them. Any inaccuracy in ordering is within reasonable bounds. However, the numerical values of the ordering are typically excluded from results. Even if the values were provided, they could have statistical significance and provide a threshold for the end of acceptable results.
Associative approaches partially meet the use-cases adaptability requirement. Seemingly any corpus of text may be ingested and then queried regardless of whether or not something similar was handled before. Even new word formations, such as new idioms, may eventually be recognized. However, processing does not change based on ingested words. New capabilities of the iterative associative depend on developer innovation.
The use-cases context requirement is not adequately met. Dialogs do not seem to be able to represent situations beyond the last utterance or ad hoc remembrance. Capturing the intent of a conversation does not seem to be done with systems based only on associative approaches.
But beyond engaging in deep dialogs, associative approaches lack other capabilities given through representing situations such as giving differences in order to support comparisons. This precludes logical reasoning such as making hypotheses in order to infer other situations and to examine inconsistencies. Possibly most apparent is the failure to adequately handle negation, which inverts the sense of a situation. Furthermore, without alternatives or changes, planning about processes is not possible.
Understanding the nuances of language seems difficult without being able to restrict word meanings to a context. For example, metaphors, which have a situation wherein only part of the meaning of words is accepted, cannot be readily represented.
Without the ability to represent alternatives, the use-cases judgment requirement is not met either. There are algorithms like particle filtering that use sensor data to make specialized decisions but the representations do not appear suited to general purpose decisions.
Associative approaches satisfy the overall normative goal to be helpful. These approaches also strive for simplicity, which makes them parsimonious.
The statistical approaches depend on well-motivated technology, satisfying the goal to be principled. The statistical approaches can be understood but the provenance of specific representation decisions, particularly with huge numbers of variables, may be difficult to determine.
The non-statistical approaches are motivated by potentially debatable mechanisms, such as how brains operate. Most non-statistical approaches use iterative algorithms that discover results after computations, which are difficult to trace. The power of their results comes from usefulness rather than understanding.
The data used in associative approaches is not small; however, the results might be compact enough to allow use without a server farm or communication to one. Currently such compact results are not provided.
Security is not publicly addressed in the implementations of associative approaches. With redundant collections or possibly other techniques, data could be separated for different user communities.
Finding associations has long been seen as an important objective for Artificial Intelligence techniques. However, relying on associations alone is not enough for general purpose computing. Not integrating logic and contexts limits capabilities. If applications need to use logic, then the applications may need to use techniques outside of the representation. Using techniques that depend on huge amounts of data also create practical issues, which are only partially addressed with substantial expense.
Associative approaches, particularly the non-statistical one, create models that may be difficult to merge, either with different kinds of information or even with just a different data set. The approach to merging seems to be adding the original new data to an existing model or starting over with data assimilation.
Natural language syntax appears to have at most a limited role in associative approaches. As with discarding stop words, mostly ignoring syntax ignores significant parts of natural language meaning.
Associative approaches are extremely popular currently because of their important uses. However, the successes may be keeping the communities that need knowledge representations from critically evaluating any issues.
Interpretation heavily dependent on the implicit context of setup
In traditional predicate logic, any quantity of predicates may apply to variables. For many words, one meaning will represent a type, which has a single argument property predicate. Each type could have its own predicate but typically some property predicates apply to many types. Axioms express the relationships between objects of different types. Adding property predicates and relationship axioms may specify ontology relationships from generic to more specific types. An approach using predicates is sometimes called symbolic, where symbols relate back to natural language words. The external representation of these approaches may include logic notation, including computer-readable formats such as KIF, graphs, or matrices of name-value pairs.
First-order predicate logic (FOL) does not allow the variables to include predicates. FOL has several extensions, which may be combined. Higher-order predicate logics allow variables for predicates that may be applied with their own arguments. Modal logics add operators to FOL that express more relationships but are properly contained within higher-order predicate logics. Frame systems support collections of entities, including processes, that express stereotypical situations or other aggregates, including objects in the style of programming languages, considered important. Some systems, particularly many rule-based frameworks and older development prototypes, express information through procedures, such as the consequence of a pattern-matching antecedent of a rule.
The following lists example implementations, and then considers how the approaches satisfy the goals and use-case requirements.
The following sample implementations that use logic with a potentially unlimited quantity of predicates are listed in roughly starting time order. The samples were chosen either because of their size or their connection to natural language understanding.
The earlier implementations faced resource limitations including memory and processor speed. Nonetheless, using a combination of a logic representation for calculations within the MicroPLANNER system of Carl Hewitt and procedural extensions, before 1970, Terry Winograd demonstrated a blocks world understanding of a restricted English with his impressive SHRDLU project at the M.I.T. Artificial Intelligence Laboratory. Before 1973, the Memory Analysis, Response Generation, and Inference on English (MARGIE) project of Roger C. Schank, Neil M. Goldman, Charles J. Rieger III, and Chris K. Riesbeck at Stanford University showed a generalized representation involving logic for common-sense English natural language. Although these projects probably helped encourage the subsequent development of ontologies, despite successes, the projects were not pursued.
About 1970,
Richard Merritt Montague introduced Montague semantics with his
The proper treatment of quantification in ordinary English
and Universal grammar
articles.
As with much of Computation Linguistics,
types distinguish semantic entities rather than single argument predicates.
The combinatorial category grammar (CCG) of Mark Steedman and his colleagues
include lambda expressions, particularly for the meaning of verbs.
In their full generality,
lambda expressions could be used for procedurally expressed semantics
but they tend to have a more restricted use.
Continuing in the same general direction, about 2013,
James Pustejovsky at Brandeis University introduced VoxML,
along with demonstrations for 3-dimensional spatial representation,
which followed on his earlier Generative Lexicon approach
to representing the semantics of natural language.
His representation resembles that of Unification Grammars
of Nissim Francez and Shuly Wintner.
In 1975, Marvin Lee Minksy at M.I.T. suggested using frames, which others, such Charles J. Fillmore with the FrameNet project at the University of California, Berkeley, University of California, Berkeley, would extend logic representations to contexts.
About 1987, Doug Lenat, Ramanathan V. Guha, and many others started the Cyc project at Cycorp, Inc. Cyc has grown to over 3 million lines of the CycL language, which has extensions to FOL including predicates as variables as with higher-order logic, quoting for meta-reasoning, defaults for non-monotonic reasoning, and a micro-theory organization that supports many collections of statements. Cyc refers to the micro-theories as contexts but they may not have sufficient detail to adequately constrain logical reasoning. This work has not been used very much directly for natural language but has provided a restricted natural language query interface.
In 1992, Michael R. Genesereth, Richard Fikes, and others participating in the DARPA knowledge Sharing Effort released documentation for the Knowledge Interchange Format (KIF), which has lead to implementations with some variations.
About 2000, the Suggested Upper Merged Ontology (SUMO) open source effort lead by Adam Pease of Articulate Software released ontology software from Teknowledge Corporation. SUMO represents information with the SUO-KIF language that has some support for higher-order logic. SUMO and its related lower ontologies represent a substantial quantity of statements, many in the form of rules that resemble the IF-THEN rules of Expert Systems.
Also about 2000, FOL syntax was gradually introduced to web documents, eventually with the RDF (RDF) and OWL (OWL) markup languages. SPARQL provides access to these representations. The ontologies represented facilitate information sharing from heterogeneous sources.
About 2002, John F. Sowa and Arun Majumdar started Vivomind, which expands on the Conceptual Graph representation of Sowa inspired by the Existential Graphs of Charles Sanders Pierce. Vivomind tries to represent more complex natural language statements.
In 2016, researchers Cleo Condoravdi, Kyle Richardson, Vishal Sikka, and Asuman Suenbuel of SAP jointly using the FOL SNARK theorem prover of Richard Waldinger demonstrated natural language database access.
Most of the approaches using unlimited predicates satisfy most of the goals and use-case requirements of Knowledge Representation. Logic using predicates is certainly principled. Predicates may, in some cases, capture too little in order to be parsimonious but nonetheless are extremely parsimonious. Being parsimonious allows the representation to be small. The unlimited predicates representations typically do not address internal information security but satisfying security goals seems reasonable.
With effort, logic can be understood. FOL, which included propositional logic, is sometimes used as a primary tool for explanations in natural language. Higher-order logic, which allows variables to range over predicates, gives a compact explanation to model many abstract relationships. Rather than using general higher-order logic to explain some other relationships, modal logic is sometime employed instead, partially for ease of understanding. There may be an impedance mismatch between using higher-order logic and representing contexts and situations, where the representation is possible but not particularly easy to understand. Nonetheless, approaches using unlimited predicates mostly satisfy the goals of Knowledge Representation.
With some exceptions, approaches using unlimited predicates satisfy the use-case requirements of Knowledge Representation. With appropriate implementations, approaches can support the access, efficiency, and scale requirements. However, such implementations may have difficulties. An implementation may be incomplete if it does not include lots of axioms, particularly for generic-specific relationships. Generalities may be hard to identify. Large implementations may obscure commonalities between concepts, making extensions from similar statements difficult to identify. Implementation optimization may be difficult when each predicate is a special case.
Implementations that rely on FOL have theoretical limitations
on their capabilities.
Nonetheless, workarounds may be available in order to make useful systems.
For instance,
a natural language front-end, like the SAP implementation mentioned above,
can ignore some modal auxiliaries, such as can
or may
,
in order to form queries.
Many time constraints, which are used to describe process relationships,
such as plans, may be covered with a few predicates.
Hypotheticals, counterfactuals, and some other situations involving context
may sometimes be interpreted within FOL.
Even with its limitations, FOL is extremely expressive.
However, for full generality in representing complex situations or contexts,
FOL is not enough: higher-order logic is required.
But even where higher-order logic is needed,
some implementations may avoid explicit representations.
For instance,
systems that need to reason about their own processing
might have predicates that specify some kinds of contexts,
which may be enough for some domain of practical use cases.
Implementations based on frames as Minsky described them are somewhat more expressive about situations and contexts. Such frames, which represent stereotypical situations, may be reasoned about as an extension to FOL. Sessions, which include dialogs, may be segregated from more global or permanent statements.
Implementations with procedural extensions potentially have the power to represent anything including contexts. But the cost of such extensions are difficulty in understanding and reasoning about the reasoning process, which can be part of use cases like decision support, automated decision-making, automated development, program synthesis, and handling natural language.
Some systems, such as Cyc, try to satisfy requirements to handle uncertainty and judgment, which relies on an uncertainty representation, with uncertainty factors. Uncertainty factors are typically attached to axioms and might represent fuzzy or probabilistic evaluations. However, implementations tend to be unclear about how such uncertainty factors may be combined. Fuzzy factors may use minimums but then the weakest statement governs the entire evaluation, which may be significantly misleading. Probability evaluations whether additively or multiplicatively combined lose their expected accuracy as combined evaluations when not properly motivated through the foundations of probability theory.
The approaches also support adaptability, where anything new may be represented, but implementations will need significant natural language understanding to form appropriate logic expressions. Moreover, with a fixed collection of predicates, however large that collection, predicates will need to be combined with a system that can represent anything. Abduction may be more difficult when commonalities between definitions are not explicitly called out.
The approaches using unlimited predicates can, in theory, satisfy most of the goals and use-case requirements of Knowledge Representation. However, managing and using unlimited predicates may be difficult.
Higher-order logic is needed to represent some types of relationships. However, using variables that represent predicates may be difficult to understand for common-sense reasoning outside of mathematics. Explicitly representing situations may be easier to understand.
With perceptual tasks and, in particular, for understanding text and eventually speech, significant uncertainty is typically the starting point. Although higher-order logic can represent uncertainty, as logic statements, uncertainty is unwieldy. Despite that, implementations seem not to have enough special handling to make uncertainty estimates useful.
Computational Linguistics, when defined broadly, claims most of Knowledge Representation except perhaps visual representations of spatial information. Computational Linguistics approaches use grammars for natural language processing. Grammars include syntax to help identify sequences in a natural language. The syntax uses the morphology of words in the lexicon. Most, if not all well-known, Computational Linguistics approaches separate the syntax from the semantics of words, using specialized syntactic representations, such as Backus–Naur Form (BNF) notation rules.
The grammars also include the semantics of words in order to differentiate valid language sequences. The semantics are typically represented with properties, functions, combinators, and lambda expressions (unnamed functions), which, in theory, have enough expressiveness to represent anything. These semantic representations and their composition with syntax have a direct mapping into higher-order logic expressions.
Below, several grammar implementations are briefly mentioned. Then, practical implications are discussed in light of some of the goals and use-case requirements that are relevant to natural language understanding.
The grammars of Computational Linguistics approaches are characterized by their syntax. Most of the syntax mechanisms of natural language grammars have patterns similar to those of context-free grammars (CFGs). However, the grammars typically have techniques that accept more general languages. Using CFG patterns improves understanding of natural language parsing.
Combinatorial category grammars (CCCs), which Mark Steedman advocates, provide combinators (functions with function arguments) for lexical items. These combinators specifically apply to items to either the left or the right in their sequence. Type-raising combinators may also be non-deterministically applied to parse a sequence. The combinators, which start as syntactic constructs, also apply to semantics. Assigning functions to lexical items is similar to Montague grammars. Unfortunately using a representation based on combinators is complex and may hinder understanding by adding an abstraction to modeling natural language.
Unification grammars, such as lexical-function grammars (LFGs) and head-driven phrase grammars (HPSGs), use CFGs for syntax with additional constraints coming from property lists, primarily of syntactic information. Some items, such as verbs have multiple argument functions that combine information, both syntactic and semantic, from neighboring items in their sequence. These functions may explain syntactic relationships but may not model semantics well.
Tree-adjoining grammars (TAGs) use trees to represent a parse. During parsing, border nodes may get replacement sub-trees. Also, interior nodes of the trees may be replaced with a sub-tree that is rooted at an original interior node and that have that nodes original sub-tree as a sub-tree of the replacement. Semantics may be handled similarly to unification grammars. TAGs have shown some of the better parsing results.
The Generative lexicon theory of James Pustejovsky parsed with a dependency grammar has demonstrated the VoxML Visualization Modeling Language to display similarities to the impressive SHRDLU project. Dependency grammars minimize the non-terminals of phrase structure grammars by creating trees with words such as verbs as non-border nodes that reference other subordinate words as nodes. The Generative lexicon theory includes lists tree structures having properties, functions, and lambda expressions for both syntax and semantics. The theory includes context information about when semantics are appropriate for lexical items.
Rhetorical structure theory (RST) and discourse representation theory (DRT) extend semantics beyond sentence boundaries. Such theories go beyond anaphora, such as pronoun reference, to include patterns of combining sentences, which must rely primarily on semantics.
Computational Linguistics approaches separate syntax from semantics in order to achieve modularity, a useful Computer Science principle called separation of concerns (SoC). Although SoC is helpful, an excessive application may be detrimental. Approaches generally that separate syntax from semantics satisfy goals and use-case requirements similarly to the satisfaction of the more general approaches discussed above that use unlimited quantities of predicates. The overall goal to be helpful is satisfied with satisfying goals to be understandable, principled, parsimonious, and small. The security goal, which implementations may satisfy through external techniques, is irrelevant to these approaches.
Although separate syntax may improve understandability, the approaches that use functions for syntax, semantics, or both may hinder it with this additional abstraction. Lambda expressions and named functions, particularly with function arguments, may require more explanation. Functions for semantics may require significant transformation to produce a logic or other actionable model.
Approaches with separate syntax tend to emphasize syntactic properties over semantics. Even though complete semantic relationships could be expressed for any token, the approaches tend to just use property predicates rather than distinguishing relationships other than for verbs. This tendency may limit the capabilities of the approaches to distinguish some semantic relationships.
Because syntax in separated, the approaches with separate syntax may not use context easily, losing distinctions from previous information or failing to see contradictions such as with counterfactuals, sarcasm or metaphor.
Current approaches with separate syntax do not seem to have robust approaches to dealing with uncertainty. For instance, when several parses may be possible, the approaches may pick only one. This may be particularly stark when dealing with erroneous syntax, where either several or no parses are appropriate, such as when dealing with sequences generated by non-native language speakers. In general, syntax parsers by themselves may not have principled ways to distinguish between several or no matches.
When new utterances appear, such as a novel word combination, syntax provides few mechanisms to adapt to a new pattern. Hand coding new rules may be required.
Separating syntax from semantics loses opportunities for more efficient parsing and integration with systems that could use semantic results. In some cases, semantic information is more suitable for distinguishing between alternatives than syntax. However, syntax is apt to applied completely before semantic information is considered.
The representation of uncertainty affects the Knowledge Representation goals of understandability and being principled. The representation also affects the separate use-case capability requirements of uncertainty, its dependent judgment, access, and efficiency.
Uncertainty may arise from several sources. Predictions, either for happenings that have not yet occurred or about which information is unavailable, have a fundamental kind of uncertainty. Measurements, as in doing perception, always have potential inaccuracies even for precise activities, such as counting, where the uncertainty may be quite small. The quantization built into measuring instruments may lead to differing estimates of similar situations measured in different ways. Interpretation adds another source of uncertainty. Differing patterns may apply to the same measurements, such different syntax rules applying to the same sequence. Interpretation, which might be performed with a variable amount of computing, based on time constraints, can give varying results. Ambiguity and vagueness have less measureable uncertainty. Estimates, which try to describe situations with uncertainty, can have uncertainty estimates about their accuracy, which can lead to a recursion about estimate accuracy uncertainty.
Handling uncertainty is built into associative approaches. Even approaches that are not explicitly derived from probability or statistics produce weighed judgments between alternatives. Such approaches while not accurately estimate probabilities may nonetheless provide reliable ordering or uncertainty estimates. Furthermore, the reliability of such approaches is based more on their results than underlying principles. Since all perception, including vision and hearing, involves uncertainty, associative approaches may have their best successes handling perceptual tasks.
Knowledge Representation approaches based on logic or syntax may not have integral methodologies to handle uncertainty. Because describing uncertainty needs sets of outcomes, called events in probability theory, fully representing uncertainty goes beyond first-order logic (FOL). More expressive logic, such as closure- or higher-order logic, can represent uncertainty but representations that stay completely within such logics may be difficult to use efficiently.
Several granularities, in generally increasing order of precision, are used to represent uncertainty: quanta, such as Likert scales; informal natural language descriptions; fuzzy values; certainty factors; upper-lower bounds as proposed by Dempster-Shaffer; ordinary probability estimates; and higher-order probability estimates of ordinary probability estimates. Since uncertainties may have several simultaneous assessments, a Knowledge Representation may need to accommodate them. Most implementations do not.
The use cases require access to the available uncertainty representations. Applications need to store, compare, and change uncertainty estimates of any supported types. For types other than probabilities, applications combine estimates as maximums, minimums, or averages. Probability estimates support more sophisticated combinations, which, except for adding independent events, typically have multiplicative formulas. For the currently rare implementations that consider estimates of conditional probabilities, the formulas can produce estimates that are extremely close to either zero (0) or one (1), the endpoints of the interval of probability values. Such estimates may not have precise numerical representations of probabilities and thus may not alternatives such as logarithms of probability estimates or an imprecise epsilon value.
In order to support use-case judgment requirements, implementation may use Bayes nets and influence diagrams, which may combine probability estimates and numerical value estimates into utilities. Since such combinations may be computationally expensive, alternative, cheaper formulas may also be used. A Knowledge Representation may need to keep track of the provenance of probability estimates and utilities derived from them.
With so many disappointing claims made for Artificial Intelligence over the decades, even the best argued proposal would be met with suspicion. Demonstrations are required. But implementations are not easy. Hence a plan is needed with justifications to show feasibility. This section discusses how and why primitives in closure logic expressions in conditional probabilities may be implemented along with a particular use case of parsing English natural language text with integrated syntax and semantics. The discussion extends to the computational environment, which includes statement merging, an overall outer loop that manages search, and approaches to temporary and persistent storage.
Gottfried Wilhelm (von) Leibniz, a German polymath and philosopher, proposed the characteristica universalis (universal characteristic), a system which could express concepts as a combination of simple elements. This idea, which was expressed before the development of symbol logic, is presented here with closure logic expressions built from a limited set of Curried predicates called primitives.
The existence of limited alphabets to express natural language, which can, in turn, express any concept, shows the theoretical possibility of using a limited set of Curried predicates but not a practical approach for computing. Instead, the evidence comes from practical explorations. The Memory Analysis Response Generation, and Inference on English (MARGIE) project of Roger C. Schank, Neil M. Goldman, Charles J. Rieger III, and Chris K. Riesbeck at Stanford during 1970-75 demonstrated that using a relatively small collection with less than forty (40) concepts could model many common sense sentences. John F. Sowa presents a significant set of distinctions based on work of the philosopher Charles Sanders Pierce. Linguist Anna Wierzbicka followed by others including Cliff Goddard identified a restricted collection of about 64 semantic primes with the Natural Semantic Metalanguage (NSM) approach to semantic analysis. NSM identifies ideas common to many natural languages.
Currently, over eighty (80) primitives have been identified in one set. The primitives were chosen to be as simple as practical and difficult to decompose. The sources for primitives have included the MARGIE project, distinctions that John F. Sowa identified from Pierce and other sources, the semantic primes of NSM, and others identified through text examples. Concepts from these sources were merged and adjusted to remove some overlaps. However, no set of primitives will be unique. The current best candidate set includes a few overlaps, such as between natural numbers and counts. Nonetheless, the current set seems reasonably stable and probably not likely to grow substantially.
The theoretical properties of closure logic, which is similar to Conceptual Graphs, has not been explored as much as higher-order logic, which uses predicates are arguments of predicates. Nonetheless, no major difficulties have been found with HOL. The proposed representation on uses one operation, conjunction, with special handling of negation and closures, upon which everything is layered. Such a simple framework should have a doable implementation.
A graphical format is currently available for manually created diagrams. The partial implementation of a graphical formula editor could allow an even easier to understand interface to debug and manipulate the representation that KIF.
Predicates have boxes with rounded corners. Entity variables have rectangular boxes. Situations, which are a special case of entity variables, visually contain predicates. Lines with some arrowheads connect predicate and entity variable boxes. As shown by arrowheads, the first argument enters its predicate, while other non-symmetric arguments leave.
To improve visual clarity, property rounded boxes are usually shown inside their entity box with touching edges instead of lines. An outermost conditionee has a dashed border. The outermost situation is omitted. Furthermore, using Rieger predicates can greatly reduce the visual size and apparent complexity of diagrams.
While not part of the internal base representation, macros may be used syntactically as predicates, called Rieger predicates. These macros can have a possibly empty association list of arguments that assign external entity variables to internal entity variables of the macro. The macros, which are expanded in the surrounding environment, provide aggregations that hide complexity and make human understanding significantly easier. Macros can provide common expressions including other logical operators and expressions for constants.
Of course, the ultimate, most understandable interface is natural language for almost any purpose outside of debugging and situations where diagrams already help such as physics or where other perceptions such as sound are directly involved.
More complex expressions can be abstracted with Rieger predicates, which can provide the other well-known logic operations, such as disjunction, implications, and quantifications, allowing the representation to be understood. Predicates can be used instead of functions. Diagrams can explain the details of more complex expressions. A partially completed visual editor could improve the human-computer interface directly to the implementation if it were completed. Even without diagrammatic representation, the external linear KIF representation is not too difficult to understand.
Conventions on assertions that the representation stores could maintain canonical forms. Some double negations can be simplified. The equal predicate can be simplified in the outermost scope. Unreachable variables, outer situations referencing inner situations, and other anomalies can be detected to prevent them being stored.
Development, although not trivial, is not unreasonable.
Initially, conditional probabilities can represent all uncertainties except epsilon values. Conditional probabilities have at least as much expressive power as more granular uncertainty measures. Maps can associate types of uncertainty measures, including the completeness of their computations, to uncertainty values and meta information such as provenance. Multiple uncertainty representations can be combined through programming language dispatch methods.
The condition and conditionee can each refer a closure logic expression.
Each conditionee (A) assumes its condition (B) by definition
P(A|B)=P(A∩B)/P(B).
A map of mappings of conditionee entity variables to condition entity variables
and back again keeps the expressions aligned.
Formulas for calculating approximate uncertainty estimates are available that should be considerably less computationally expensive than calculating a full Bayes net and not require estimates for all negative conditions.
Estimates of many conditional probabilities may at first be made manually. Experts can give more reliable estimates for situations where the closure is well specified. In many cases, the accuracy of the estimates may not affect the overall result. Eventually, enough statistics may be available to compute estimates rather than making them manually.
Some systems using probability estimates combine them by taking averages or do not consider them as conditional probabilities. In such cases and with other coarse combinations of uncertainty estimates, the combinations can become less reliable than their inputs. On the other hand, with appropriate formulas using conditional probabilities, estimates may converge to more accurate values as more information is provided.
An approach has been devised to improve parsing of natural language with semantics. Closure logic expressions encode syntax rules from handling morphology to combining phrases or catena into representations of sentences and eventually larger aggregations. The integrated logic encoding of syntax and semantics allows parsing the highest utility combinations first. These best first combinations can avoid trying less important combinations and can allow partial results to be used immediately with a follow-on of more detailed and more reliable combinations.
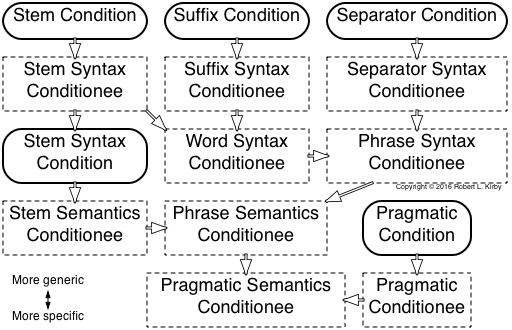
For instances of words with many meanings but a single syntax type, such as noun, the word stem conditional probability for just the syntax type can be combined with the morphology conditional probability to produce a word syntax-only conditional probability. A conditional probability includes a condition and a probability estimate for a conditionee. Conditional probabilities for at least two words, separators between them, and a possible syntactic arrangement can be combined into a syntax-only conditional probability for a phrase or catena. For a better conditional probability, the semantic conditional probability, which includes a syntax-only conditional probability, can add to the syntax-only phrase conditional probability. In yet another layering, pragmatic conditional probabilities such as for closure can even further help decide if the semantic conditional probability fits.
Abstract non-terminal entities enable the bookkeeping of parsing. Each non-terminal has a collection of the times that subordinate message parts were encoded in their media, such as text. A non-terminal for each token has its corresponding message part and a part of speech relation that names the part of speech and identifies the primary entity that the message part models. The non-terminal for a token includes expressions of the morphology such as number for nouns. Other non-terminals have expressions that refer to the non-terminals of their subparts to form a directed acyclic graph (DAG) or sometimes a tree of non-terminals.
One of the most common operations on conditional probabilities is combining its logic expressions, either the condition or conditionee, with corresponding expressions of other conditional probabilities. Combining involves finding which entity variables from different expressions can be combined and which cannot. Entity variables that have the same properties and corresponding relations with corresponding entity variables between expressions are better candidates to be consolidated into a single entity variable in the result.
If a sequence follows syntactic standards, then an algorithm to combine expressions while parsing may operate in linear time of the expression complexity. Otherwise, a more complex algorithm, such as A-star (A*), combines expressions using heuristics based on utilities, taking a less determinate amount of resources. The heuristics that the A-star algorithm uses can reuse the results from trying the previous, simpler linear combination method. Heuristics can balance costs from matching entities according to properties and relations with costs from not matching entities. The details of the heuristics are described elsewhere.
The costs computed for each combination can be normalized with respect to the lower bound of the cost available at the start of merging. The normalized cost can then be part of the formula to compute the new conditional probability of each combination. When the cost is considered the new conditional probability can be higher or lower than that of any of the original conditional probabilities. Thus even though the words of a sentence may each have several meanings, each with a low conditional probability, the estimated conditional probability of one particular parse that properly combines syntax and semantics can be nearly one (1.0).
An outer loop runs implementations of test use cases of the Knowledge Representation. The outer loop may evoke a architecture-limited quantity of simultaneous activities when the computational architecture supports parallel processing. Structures for steps maintain state before and during activities. During runs, the outer loop evokes modules that, although not part of the core, provide expected behaviors to interface with the core.
The outer loop supports an implicit A-star algorithm that can share utilities about potential steps with inner algorithms for expression merging. While the A-star algorithm tries to minimize total costs, combinations of the already calculated cost and a heuristic to reach a goal, the implementations use the inverse of benefits as measured with utility, which is defined as expected value. Using utilities supplies a principled approach to creating heuristics.
The utilities may be dynamic. The conditional probability of a proposed expression merger might be an upper bound, which might be lowered while possibilities are explored. The value of some component of a possible combination could initially be the value of the combination. As alternatives are simultaneously evaluated, a component might be devalued as it becomes less important toward producing a combination.
Modules will perform logic simplifications so that nearly canonically formed expressions are stored. Bare double negations may be simplified. An equality predicate in the global scope of an expression may be collapsed. Redundant stand-alone predicates implied by a universal quantification (∀) may be removed. During the search for simplifications, improper references from outer situations to enclosed inner predicates can be handled as errors.
Modules will evoke text-processing capabilities for the initial demonstrations. They will tokenize input into tokens and separators, identify stems or lemmas and suffixes, create appropriate conditional probabilities for those text parts using templates for the condition and a lookup of any conditionees, and assign times to them. Steps will be created to merge conditional probabilities for stems or lemmas and suffixes into token conditional probabilities. Steps will then be created to merge conditional probabilities for separators and tokens or larger groupings.
Since the core Knowledge Representation has few operators and does not include functions, modules will produce measurements to be added as predicates to logic expressions. Measurements may include counts, combined times, orderings, distances, or others as capabilities expand.
Modules will interact with the computing environment. Modules will obtain text and marshal text generation. Modules will evoke external capabilities such as theorem provers or database access. Modules will decide what conditional probabilities are given long-term storage. Modules will manage both short and long term storage, suggesting consolidations and pruning unwanted conditional probabilities.
A single internal representation will be used for merging expressions, short-term internal memory, and longer-term storage, which potentially could have tiers of permanence or shards. Both short-term internal memory and longer-term storage can use the same index structures.
References from specific to more generic conditions are the only intrinsically supported inference. When a condition is retrieved, any more generic conditions may also be needed to compute the best estimates of conditional probabilities. Thus, condition lookup will be the most time-sensitive and frequent operation. Conditionees and conditional probability estimates will be attached to conditions. Each condition will directly refer to the most specific of its more generic conditions, which gives indirect access to the entire DAG of more generic conditions with access to most significant for calculations first. Each direct reference includes mappings of entity variables between expressions of the generic and specific conditions and possibly other relevant meta-data.
Stored data is assumed to be in nearly canonical format. There can be no further simplifications for double negations or global equality predicates. When a condition is more specific because of equality of entity variables of a more generic condition, the equality is captured in their entity variable mapping. Entity variables of a generic condition are mapped to the variable of a more specific condition with the universal quantification idiom that makes them redundant.
An expression for a candidate condition can be found if already available in the store. The lookup accounts for any permutation of the entity variables between candidate and found expressions. If the candidate was not already in the store, it is added along with indexes allowing the candidate to be found by any subsequent search.
After a condition in the store is identified, its conditional probabilities with conditionee expressions may be retrieved, added, updated, or deleted. Meta-data of the condition may also be manipulated. Appropriate optimistic locking keeps the internal data structures consistent. More complex locking will be needed for an external store.
Some indexes may be explicitly implemented to allow special cases of navigating from generic to more specific conditions for particular properties, such as a spatial bounding box. However, most such navigation will only be available through using the conditionee of a condition as a condition itself or through merging conditions into a very specific condition whose more generic conditions are examined.
The Clojure implementation will initially access a SQL database (PostgreSQL) for external storage. The SELECT WITH RECURSIVE statement can return all more generic conditions of a specific condition.
Test example sentences guide this research and software development. Through an iterative, initially manual, interactive process, primitives are selected for any situation encountered; word meanings are identified and represented; and syntax is identified, decomposed, and piecewise represented. Using the representation of parts, software will have goals parse example sentences, integrating their punctuation, word stem (or lemma), and word suffix meanings into a combined representation.
Eventually, more encoded information will allow actions for some examples, such as imperative and interrogative sentences. Such actions will show how a system can be embodied in the world.
After enough vocabulary is developed manually, perhaps several hundred of the most frequently used words and probably nearly all pronouns, conjunctions, and prepositions, a system may represent meanings and glosses of word definitions to further expand vocabulary iteratively and automatically with supervision. Then a system with an expanded vocabulary may further refine itself beyond word meanings through reading more general materials. A myriad of uses are foreseeable.
The following sentences are planned for initial development:
Show "Hello."
This two word, imperative sentence, even though short, involves a verb, spacing, a quote, and quoted punctuation. This short sentence tries to limit scope to promote software development. Even processing such a short example may lead to inappropriate partial representations before arriving at the best complete representation. Eventually, a system will need some self-awareness to perform the request.
Make an application that shows the text "Hello, world!"
This imperative sentence has several features: determiners, a subordinate clause, an internal reference, personification, an appositive, and a quote of an interjection, an address, and punctuation. This sentence demonstrates a potential system use, automatic programming, which requires non-linguistic information.
A boy hit a ball.
This declarative, past tense sentence involves natural kinds, which involve modeling entities outside of a system on a computer. With enough background information represented, this sentence could presume several scenarios, making best guesses for a potential dialog.
Was it white?
This interrogative sentence, involving a copula, anaphora, and a modifier, could follow as part of a dialog with the previous sentence. The representation of an answer might either describe a negative or, with enough background, hypothesize a positive scenario.
This document suggests a current snapshot of a long-term development effort. A collaboration web site has been established with the JBoss J2EE implementation. Primitives, a very few word meanings, mostly as diagrams, and some English language syntax rule diagrams have been collected. Much more remains to be done.
Code will mostly be written in Clojure to run within the JBoss environment,
which runs on the Java virtual machine (JVM).
However, the code will not depend on JBoss.
Test cases need to be constructed.
Heuristic evaluation will be written for the primitives,
which can be matched when combining the entity variables
of closure logic expressions.
Infrastructure will include in-memory storage structures.
English language ingestion will include recognizing separators,
such as spaces and punctuation and stemming,
such as the Porter or Krovetz
(Kstem)
stemmers, or lemmatization.
An outer loop
will turn sentences into a representation
to demonstrate feasibility.
The demonstration may include facts for performing the actions
of an imperative sentence.
A demonstration will help verify
the appropriateness of the selection of primitives.
Next, perhaps 1,500 words that have been listed in the Globish vocabulary will have their definitions encoded. The outer loop will be extended to explicitly parse the glosses of dictionary definitions to allow definitions to be built from existing word meaning representations. Responses in natural language will eventually allow dialogs. An earlier effort to show the representation as diagrams might be resurrected. There are many possibilities for improving the development interface.
The effort is aimed at commercialization rather than creating open source. A really good search engine front-end, perhaps for shopping, could be an easy target, which could be extremely valuable. No one has yet made the altruistic case for open source development.
This web site provides tools to collaborate on finding a limited set of primitives, which are rudimentary ways of differentiating information. The primitives will characterize constraints, which when combined in logic expressions, will be able to differentiate all information. The constraints may be properties having one parameter, binary relations, or more complex relations of three or possibly more parameters. The constraints may be combined into closure logical expressions rather than just first-order predicate-logic expressions. Such closure logical expressions provide conditions and outcomes of conditional probability expression, which can represent knowledge.
This document offers information and opinions based on what its author has encountered. It is not complete or even comprehensive. This document may be incorrect, particularly when trying to describe proprietary technology or technology that the author has not closely studied, which is the case with most large systems. The author invites comments, extensions, and corrections.
Only a few pages are visible without logging in.
Copyright © 2019 Robert L. Kirby. All rights reserved.